Home >> Documentation
This is documentation about the website.
Quick start What is forced alignment What is untrained forced alignment How to prepare the transcription file How to prepare the audio file How to prepare the dictionary file What can I do with the TextGrid produced by the alignment How to perform the alignment on your own computer Generating dictionaries automatically How to prepare the ARPAbet equivalence file How to generate a dictionary automatically What is a 3-column dictionary When to provide dictionaries or 3-column dictionaries Using diacritics and Unicode in dictionaries and transcriptions How to generate the dictionary on your own computer Extracting phonetic data from the aligned TextGrid How does phonetic extraction work How to manually verify and correct the alignment How to extract phonetic information on your own computer Generating a vowel triangle What is a vowel triangle and what can I use it for How to generate the triangle How to generate the triangle manually on my own computer Replace ARPAbet with your original glyphs How does ARPAbet replacement work How to replace ARPAbet on my own computer Data and confidentiality Will my files be kept on a server? Will the data be aggregated in any way? Credits and support
This website is an interface to the FAVE-align computer algorithm. This interface is geared towards using languages other than English, and is meant in particular for usage with Indigenous languages, and other languages for which it would be too expensive to build custom machine learning tools.
Examples:
Cooks Islands Māori Praat TextGrid and sound file
Spanish Praat TextGrid and sound file
How to open these files
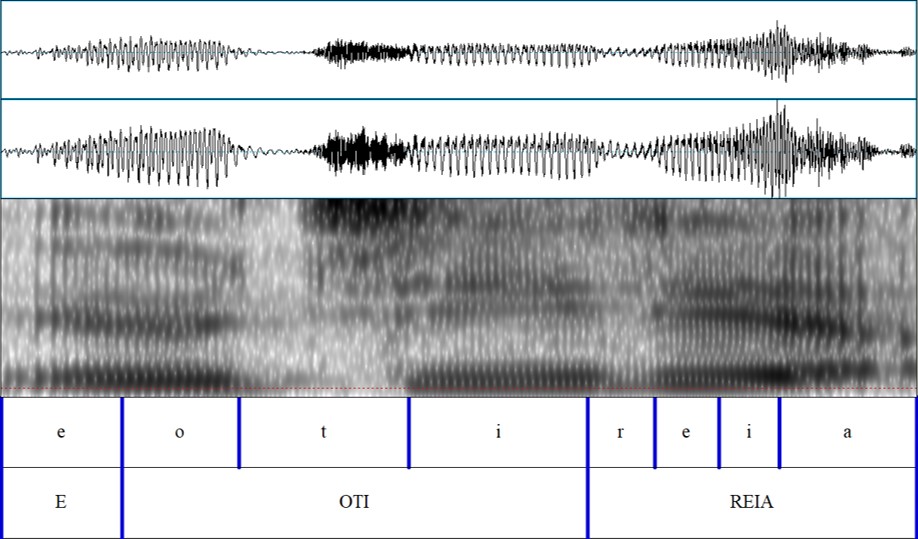
e oti reia are matched with the parts of the audio signal where they words are said, down to the level of individual vowels and consonants. Notice how the areas aligned with vowels have darker stripes, as well as big and regular vibrations. These are the telltale signs of your vocal cords vibrating to produce a vowel.
This alignment is called "forced" because the computer is doing its best to try to guess where sounds begin and end. This is difficult to identify, as sounds frequently blend when they are produced in everyday speech. There is always a certain degree of error that has to be hand-corrected. However, making these aligned transcriptions manually is an extremely slow process, and forced alignment makes the process approximately 30 times faster.
The examples above are in the TextGrid format of the Praat phonetics analysis software. We can use aligned text to study the phonetic characteristics of speech. For example, we can determine the range of variation of the vowels in our language.
There are many excellent aligners that you can use (e.g. Montreal Forced Aligner, WebMAUS, EasyAlign, and the aligner in Kaldi). They have premade machine learning models and dictionaries for numerous languages. Here, we will use the FAVE-align program.
What happens if you don't have a premade model for your specific language? Making models takes a lot of data, and it can be difficult to compile the amount of data necessary for the computer to learn to identify the sounds of a language. Here, we are going to skip that requirement, and use pre-existing models for other languages to "bootstrap" the alignment of our language.
How do we do this, we are going to create a dictionary where we will approximate the words of our language to English sounds. This will make the algorithm believe that the "a" sound in our language sounds a little bit like the "a" in English bat, or that the "p" sound in our language sounds a little bit like the "p" in English pet. The correspondences are not going to be perfect, and there will more error in this alignment than if we were aligning English. However, this will dramatically accelerate the process of aligning our transcriptions, allowing us to benefit from existing machine learning techniques.
Examples:
Cooks Islands Māori transcription and sound file
Spanish transcription and sound file
The transcription file is a text file with five columns, separated by tabs. The following is an example in Cook Islands Māori (you can download the files above).
Jean |
CIM |
0.14 |
1 |
e oti reia |
Jean |
CIM |
1.6 |
2.6 |
ā |
Jean |
CIM |
4 |
4.96 |
te openga i reia o tērā |
The file is a plain text file with UTF-8 encoding. The first column has the name of the speaker. The second column has the prefix for the two tiers that will be generated (with the words and the phonemes). The third column has the start time of each group of words (in seconds). The fourth column has the end time of each group of words (in seconds). The fifth column has the transcription. The transcription should only include alphabetic characters. It should have no numbers or punctuation symbols.
If you have your data transcribed in ELAN, you can use export your data into the five-column format. First, go to File > Export As > Tab-delimited text.
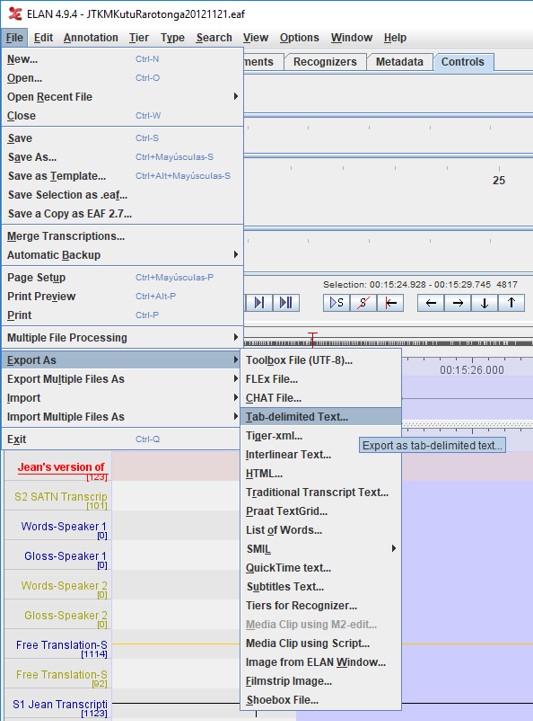
This will open the "Export tier(s) as tab-delimited text" window. First, click on "Select None" to clear all selection. Then, import the one tier that has the transcription you want to align. (Try to do only one speaker each time). Include the "Begin Time" and the "End Time", and make the time format in seconds (ss.msec). Finally, click on "OK" and save the file as a UTF-8 text file.
You need to provide a Wave file of less than 500MB. You can use Praat, ELAN or Audacity to extract portions of your audio file.
Examples (to use with the example transcriptions):
Cooks Islands Māori ARPAbet dictionary
Spanish ARPAbet dictionary
If you are aligning English speech, with common English words, then you do not need a dictionary file. However, for all other languages, you will need to provide an additional dictionary that contains all of the words in your transcription.
The dictionary file specifies a correspondence between a word and its pronunciation. This should be a two column tab-separated file, with the word in the first column and its pronunciation in the second. Pronunciation must be encoded using the Arpabet system. You can use this PDF to help you with the conversion: List of ARPAbet characters. In the pronunciation column, phonemes are separated by spaces. Although Arpabet allows for marking of secondary and tertiary stress, for best results it is recommended to mark primary stress on every vowel.
Arpabet is very limited. In the event a suitable phoneme is not found, its closest Arpabet equivalent should be used. For example, we've found that glottal stops can be replaced by English T or K (CITATION). Suprasegmental features such as tone and vowel length needs to be ignored at this stage. For example, both "a" and "ā" are represented using ARPAbet AE1. The length distinction can be recovered later, when the Textgrid is converted back to your languages characters.
The following is an example of a dictionary for Cook Islands Māori data, containing the word in the example transcriptions:
ā |
AE1 |
e |
EH1 |
i |
IY1 |
o |
OW1 |
openga |
OW1 P EH1 NG AE1 |
oti |
OW1 T IY1 |
reia |
R EH1 IY1 AE1 |
te |
T EH1 |
tērā |
T EH1 R AE1 |
Go to Praat. Go to "Open" >> "Read from file" and open both your TextGrid and the wave file. Select both of them (holding down the CTRL key and clicking on them). Then, click on "View and Edit". This will show the window with both the alignment and the sound wave.
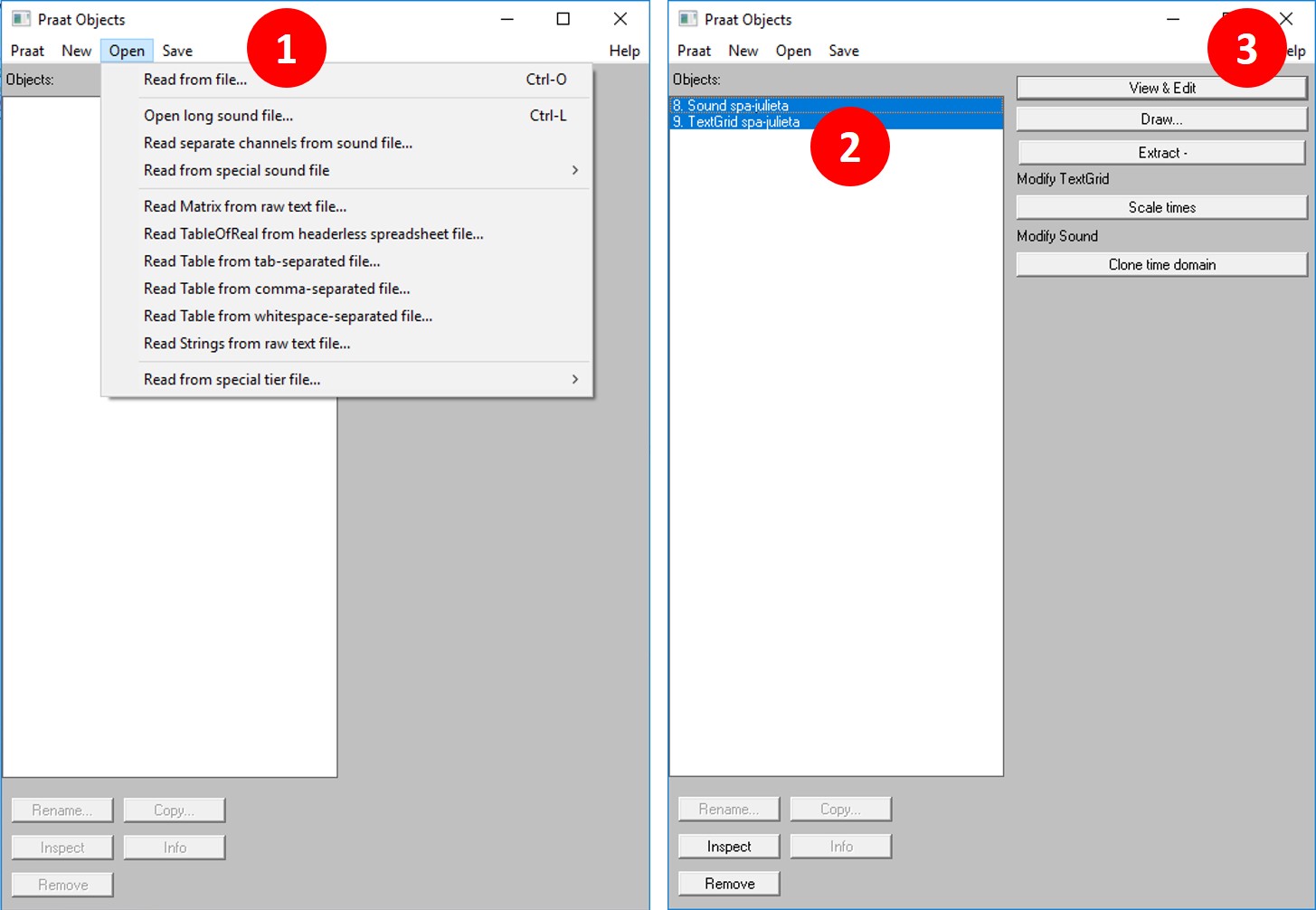
You can see an example of the window below. To zoom into a particular word, first select the region of the sound in the spectrogram window (the middle window). To select, click your mouse on some part of the spectrogram, keep it clicked, and then more left or right, just as you would select words in a word processing program. Once you have selected a region, go to "View" >> "Zoom to selection". This will allow you to see each word and vowel in detail.
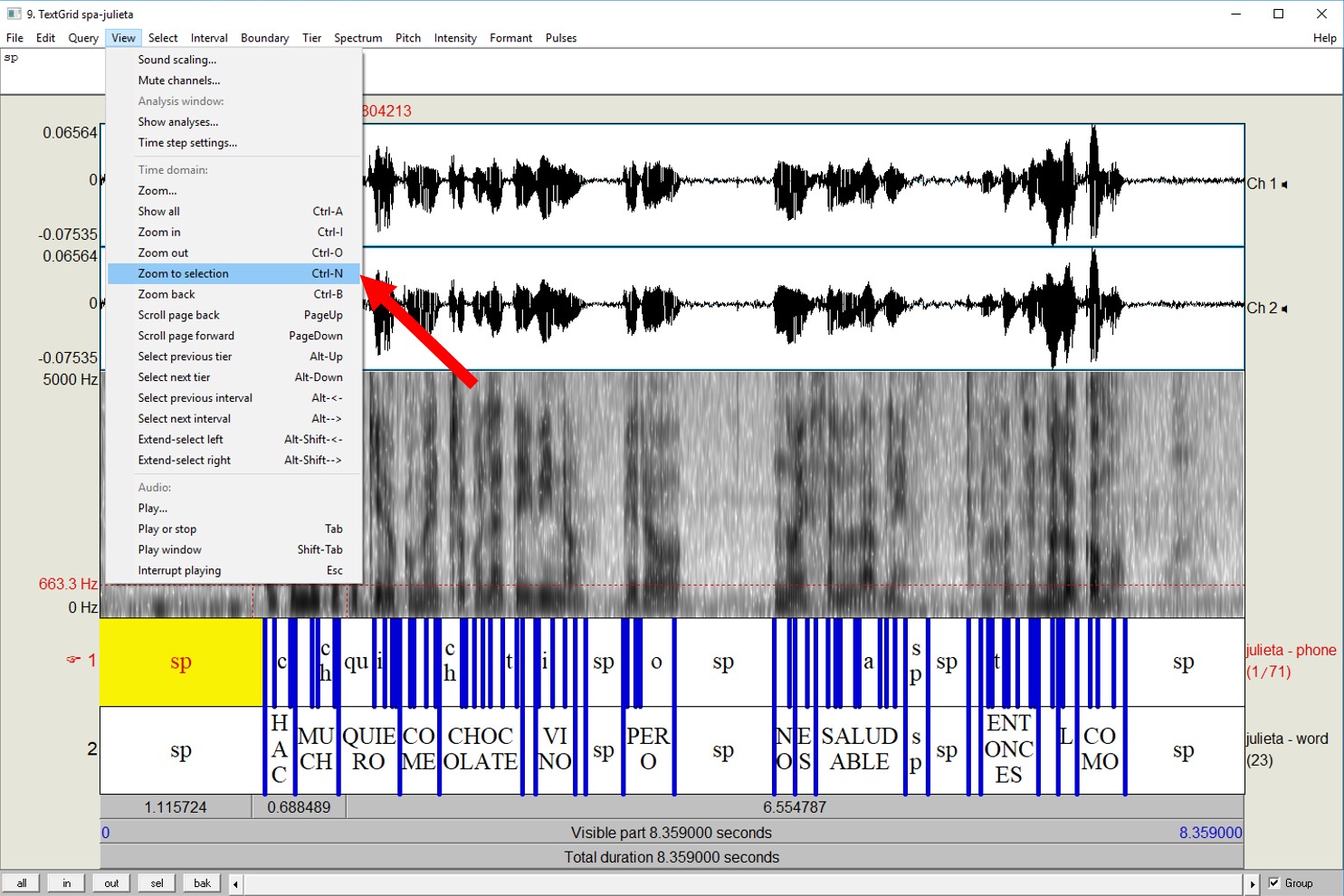
Here, you can also manually correct for any errors that the aligner might have made. [INSERT LINE ON CORRECTING THE TEXTGRIDS].
If you don't have Docker, you will need to install it by going to https://docs.docker.com/install/. (If you have Windows 10 Home, or some other Windows that doesn't support the full Docker, you can install the Docker Toolbox: https://docs.docker.com/toolbox/toolbox_install_windows/). If you don't have the files for FAVEalign, you need to download them into your computer. First you''ll need HTK 3.4.1. You can get it from the URL below. http://htk.eng.cam.ac.uk/download.shtml Next, go to the Docker Quickstart Terminal and download the files of FAVEalign from GitHub. git clone https://github.com/JoFrhwld/FAVE.git Next, you will need to update 5 files. You''ll need to get the files from here. https://github.com/JoFrhwld/FAVE/pull/40/files Using the Docker Quickstart Terminal, go to the folder where you saved the files and run the installer: docker build -t fave c:/fave
The main difference between regular forced alignment and untrained forced alignment is that we are going to be making the dictionary believe that the words in our language are "new" words of a language it already speaks. This section explains how to create custom dictionaries that make our words sound like English words to the machine learning system. This is necessary if we don't have enough data to train a language-specific alignment model.
Examples (to use with the example transcriptions):
Cooks Islands Māori ARPAbet equivalences
Spanish ARPAbet equivalences
The equivalence file has two tab-separated columns. The first column has the letter in the orthography of your language. The second column has the closest ARPAbet equivalence. This file will be used to automatically generate a dictionary from your transcription file. Make sure the file is UTF-8. (Internally, the system converts files to UTF-8, and eliminates the BOM character out of the UTF-8-BOM files produced by some Windows programs).
In the Cook Islands Māori example below, the vowel 'a' is said to be equivalent to the ARPAbet AE1. Notice that there can be more than one character on either side. For example, the digraph 'ng' is equivalent to ARPAbet NG. Some differences are flattened out: The difference in vowel length between 'a' and 'ā' is not preserved in Arpabet. (This will be recovered later, when you convert the TextGrid back to your orthography). There are sounds which have no good ARPAbet equivalence. For example, the glottal stop is represented using a T, based on research by [CITATION] and [CITATION]. THE SYSTEM USES UTF-8, BUT WE ARE WORKING TO EXPAND IT TO PROCESS LANGUAGES WITH WRITING SYSTEMS FROM INDIA.
a |
AE1 |
ā |
AE1 |
e |
EH1 |
ē |
EH1 |
i |
IY1 |
ī |
IY1 |
k |
K |
m |
M |
n |
N |
ng |
NG |
o |
OW1 |
ō |
OW1 |
p |
P |
r |
R |
t |
T |
u |
UW1 |
ū |
UW1 |
v |
V |
' |
T |
Here's a second example, an ARPAbet equivalence for Spanish. This example has digraphs (e.g. "ch"), but it also has sets of two letters to the left, which have two ARPAbet equivalences to the right. In Spanish, the letter "c" can be pronounced like a "k" in casa, but like an "s" in Cecilia. This dictionary reflects these differences. Notice also that the letter "h" by itself is represented by a single blank space. The blank space can be used to represent letters that are silent, such as the "h" in Spanish hasta. Finally, the palatal sound eñe ("ñ") has no equivalent in English, and so we will use N to represent it temporarily.
a |
AE1 |
b |
B |
c a |
K AE1 |
c e |
S EH1 |
c i |
S IY1 |
c o |
K OW1 |
c u |
K UW1 |
ch |
CH |
d |
D |
e |
EH1 |
f |
F |
g a |
G AE1 |
g e |
HH EH1 |
g i |
HH IY1 |
g o |
G OW1 |
g u |
G UW1 |
g u e |
G EH1 |
g ü e |
G W EH1 |
g ü i |
G IY1 |
g u i |
G W IY1 |
h |
(ONE SPACE) |
i |
IY1 |
j |
HH |
l |
L |
ll |
JH |
k |
K |
m |
M |
n |
N |
ñ |
N |
o |
OW1 |
p |
P |
qu |
K |
r |
R |
s |
S |
t |
T |
u |
UW1 |
v |
B |
y |
IY1 |
y a |
JH AE1 |
y i |
JH IY1 |
y o |
JH OW1 |
y u |
JH UW1 |
z |
S |
Go to the page to Generate a dictionary, or add new words to an existing dictionary. There, select a transcription file and the ARPAbet equivalences file. If you want to generate a dictionary from scratch (from just the transcription in the transcription file), you don't need to provide a previously existing dictionary. If you already have a dictionary, you can augment it by providing it to the system.
When we made the dictionary, we erased many of the differences amongst the sounds of our language. For example, in Cook Islands Māori, the short vowel "a" and the long vowel "ā" were represented using the same ARPAbet glyph, AE1. The 3-column dictionary is a tool that takes the ARPAbet in the TextGrid and recovers all of the differences that you erased when you made the dictionary.
The following is an example of a 3-column dictionary for Cook Islands Māori. This has three columns separated by tabs. The first two columns are identical to the dictionary file. The third column has the same letters as the first one, but the letters are separated by spaces. Notice that the number of letters in the second and third columns are the same. For example, the word "tērā" has four ARPAbet glyphs (T EH1 R AE1) and four glyphs in the third column (t ē r ā). The system will look for the word "tērā" in an aligned TextGrid, and then replace the ARPAbet glyphs with the glyphs in the third column. By doing this, we will be able to differentiate between short and long vowels in the TextGrid.
ā |
AE1 |
ā |
e |
EH1 |
e |
i |
IY1 |
i |
o |
OW1 |
o |
openga |
OW1 P EH1 NG AE1 |
o p e ng a |
oti |
OW1 T IY1 |
o t i |
reia |
R EH1 IY1 AE1 |
r e i a |
te |
T EH1 |
t e |
tērā |
T EH1 R AE1 |
t ē r ā |
The system will automatically give you the dictionary and the 3-column dictionary based on your transcription. Optionally, it will also include the words you gave it in previously existing dictionaries.
The autogeneration of the dictionaries can fail for a number of reasons. Maybe there are two words that are spelled the same in your language but pronounced differently. If this is the case, then you may want to manually change the transcriptions. If you want these changes to carry on to future versions of the dictionary, then you will need to provide the manually modified dictionaries to the webpage.
We are working to make the system fully compatible with diacritics in different systems. The system uses UTF-8. If you use other formats, the system is programmed to try to convert your input to UTF-8.
We have detected additional issues in using Unicode characters, in particular characters from Indian scripts. We are working to expand the capabilities of the aligner program to handle these characters.
Internally, the system is using a Python script to generate the dictionaries. You can find the script here on GitHub: http://github.com/rolandocoto/forced-alignment/blob/master/makeArpabet.py. The script uses Python3 print commands.
The main reason why we want audio aligned with its phonemes is so that we can study the phonetic properties of the language. Praat can automate the extraction of phonetic information, so that work like studying vowel variation can be done more rapidly.
BEFORE YOU DO THIS EXTRACTION, WE URGE YOU TO MANUALLY CORRECT THE TEXTGRID TO MAKE SURE THAT THE ALIGNED INTERVALS DO IN FACT CORRESPOND TO THE SOUNDS THEY REPRESENT.
The system can extract the following phonetic information from the recording and its accompanying aligned TextGrid.
To get this information, go to the page to Extract phonetic information from a wave file and an aligned TextGrid, and give the system a wave file and its accompanying TextGrid. The other options refer to settings within Praat to fine tune the extraction. The system will generate a text file containing the phonetic information.
Manual correction of the TextGrid is recommended. This is especially vital for phonemes which are an imperfect overlap with ARPAbet. To manually correct the TextGrid, open the TextGrid and wave file in Praat, and move the boundaries on both the phoneme and word tier to be aligned with the audio. Save the resulting TextGrid as a separate file and use it as subsequent input for following processes.
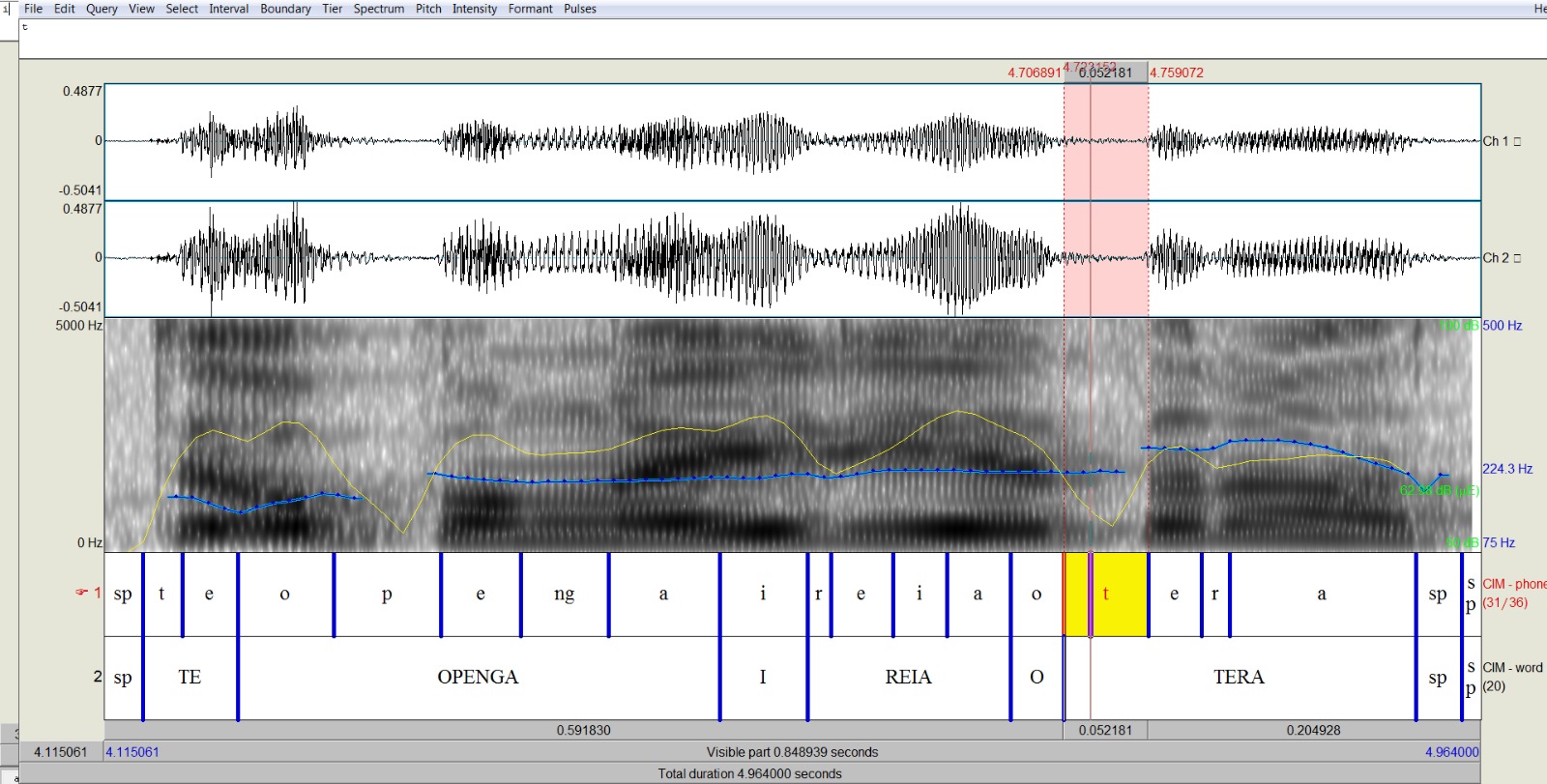
The system uses a Praat script to extract the phonetic information. You can find the script here on GitHub: https://github.com/rolandocoto/forced-alignment/blob/master/getPhonetics.praat. In order to run the script, you will need to download the Praat phonetics analysis software.
When we use the dictionary, we have to erase some distinctions (e.g. between short and long vowels, or between vowels with different tones). Here we will recover those distinctions and reconstruct them in the TextGrid.
The script uses the 3-column dictionary to replace the ARPAbet glyphs in the phoneme tier of the aligned TextGrid. The script turns those ARPAbet glyphs into the orthography that you are using to represent your language. (This is the orthography you used to write your transcription and your ARPAbet equivalence files). For example, the following are a couple of lines from the Cook Islands Māori 3-column dictionary:
i |
IY1 |
i |
reia |
R EH1 IY1 AE1 |
r e i a |
o |
OW1 |
o |
tērā |
T EH1 R AE1 |
t ē r ā |
On the left side of the figure below, you can see the TextGrid as it looks when it comes out of the aligner. The phonemes in the first tier are in ARPAbet. When you replace the ARPAbet, the script looks for each word, and then replaces each ARPAbet character with its assigned orthographic representation, which is in the third column. The final product is the TextGrid shown on the right. For example, in the word TĒRĀ, the ARPAbet T is replaced by t, EH1 is replaced by ē, R is replaced by r, and finally AE1 is replaced by ā. Notice that, when we do that, the distinction between long and short vowels reemerges in the resulting TextGrid. Now, the long vowel at the end of TĒRĀ is written differently from the short vowel at the end of REIA. Doing this, we can get back all the distinctions we were forced to abandon when we were creating the dictionary.

The system uses a Python script to extract to replace the glyphs in the TextGrid. You can find the script on GitHub: https://github.com/rolandocoto/forced-alignment/blob/master/fixtextgrid.py. The script uses Python3 print commands.
A vowel chart can be automatically generated using this site using the phonetic information extracted from audio as input.
A vowel chart is a schematic showing how the vowels in a given audio are arranged in spectral space (i.e. the values of their principal formants) as well as give an indication of where in the mouth they are produced. This visualization can serve several purposes. First, it can help illuminate the nature of overlap or spread among vowels. It can also illustrate speaker variation if the input is from several speakers, or show a comparison across language varieties.
Using the phonetic information extracted from this page Extract phonetic information from a wave file and an aligned TextGrid, you can produce a vowel chart that will plot each vowel that has been extracted by its F1 and F2. Navigate to Draw a vowel triangle https://icldc-align.appspot.com/uploadForTriangle.jsp and upload the phonetic information. It is recommended to keep the default settings unless you are comfortable with phonetic analysis, but you are able to specify a minimum and maximum value for F1 and F2 values if you desire. After clicking “Generate vowel triangle,” manually click the vowels you would like to plot.
[EXAMPLE IMAGE]
What is produced is a vowel chart of each vowel from the phonetic information with the standard deviation for each vowel indicated by ellipses.
The system uses an R script to draw the vowel triangle. You can find the script here on GitHub: https://github.com/rolandocoto/forced-alignment/blob/master/drawTriangle.r. In order to run the script, you will need to download and install R, as well as the phonR package.
We understand that your data might be sensitive and confidential. We have designed the system to delete information and uploads are not retained after their products are emailed to the user's specified email. If you would like us to retain your data in order to improve system usage, please contact us. This would be particularly useful if you have pre- and post-manually corrected TextGrids that result from the aligner.
No. After each process completes, the data is deleted from the server.
No. After each process completes, the data is deleted from the server.
You can read about the credits in the software credits and acknowledgments page. You can ask Rolando for immediate help if you need it.
This tool was developed for a workshop at the International Conference on Language Documentation and Conservation 2019, organized by the University of Hawai'i at Mānoa. It was developed by Rolando Coto from Victoria University of Wellington, Samantha Wray from New York University Abu Dhabi, Sally Akevai Nicholas from Massey University and Tyler Peterson from Arizona State University. (Read here for the full credits of the components).
This tool is in development. For feedback and questions, please contact Rolando Coto.
Last updated: April 3rd, 2019.